Knight Battle
이번에는 근접 전투를 학습시켜 보았다. 방패, 검을 들고 제한된 공간에서 제한 시간까지 전투를 진행하는 시나리오로 구성했다.
Hp, 스테미나가 있으며 공격 Action 을 취하게 되면 스테미나를 일정 소비한다.
먼저 일대일 전투를 학습시킨 뒤 이를 응용해 다대다 전투를 협동 학습을 통해 진행할 것이다.
Action
DiscreteAction 4개를 사용할 것이며, 구성은 다음과 같다.
- 앞뒤 움직임 (2)
- 좌우 회전 (2)
- 좌우 움직임 (2)
- 액션 (0 - None, 1 - 방패 사용, 2 - 검으로 공격)
방패 사용과 검으로 공격이 한 액션으로 묶여있기 떄문에 공격과 방어는 동시에 할 수 없다.
Observation
| sensor.AddObservation |
|---|
| 자신의 Hp |
| 자신의 스태미나 |
| 현재 공격이 가능한지 여부 |
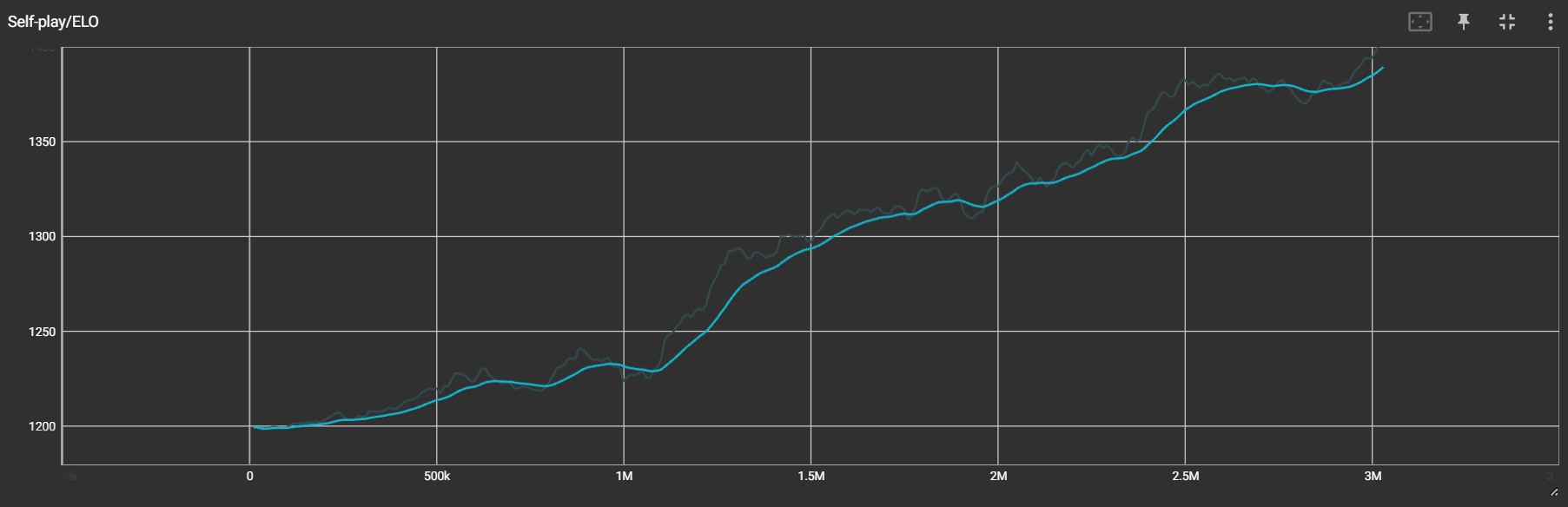
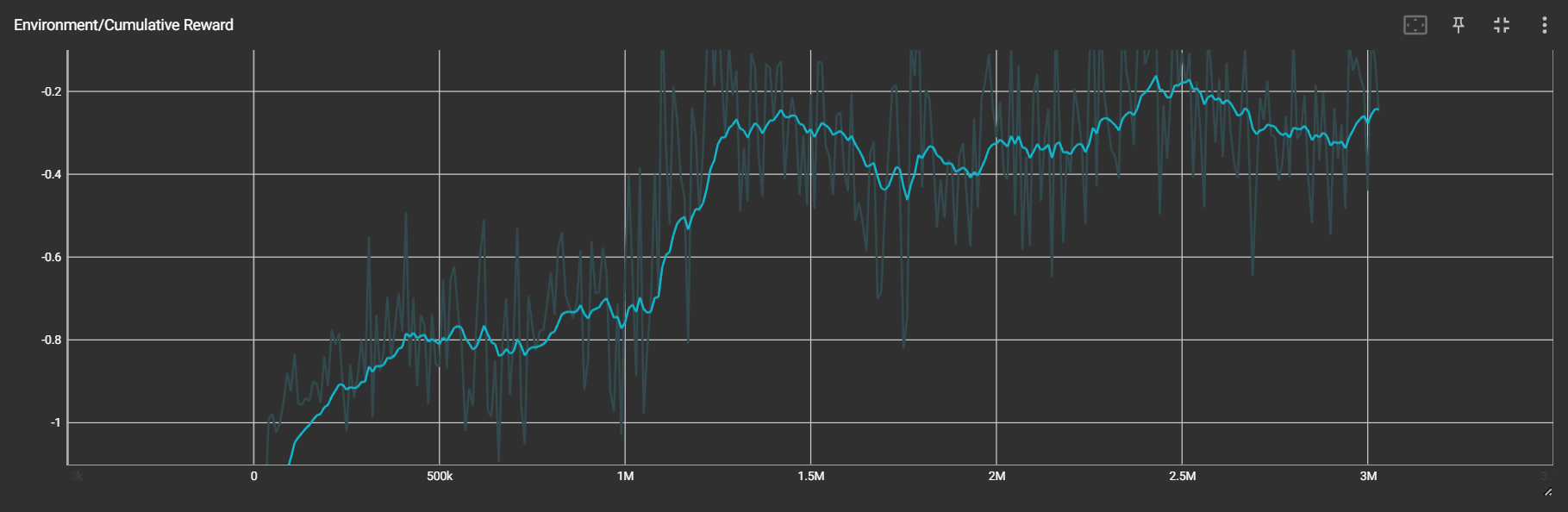
1 vs 1 Train (Back Shield Enabled)
일대일 전투는 두 Agent 의 Team-Number 는 다르게 설정하고, Behaviour Name 은 같게 하여 모델은 공유하게 만들었다.
둘 중 하나가 사망하거나 제한 시간이 지날 경우 에피소드가 종료된다. 이때 남은 Hp 에 따라서 Reward 를 다르게 주었다.
제한 시간은 1000 Step 이다.
Policy
| Situation | Reward | EndEpisode |
|---|
| 매 Action 마다 (Living) | 틱당 -1 / (MaxStep) | |
| 장애물에 닿았을 시 | 틱당 -5 / (MaxStep) | |
| 공격에 성공했을 시 | 0.2f | |
| 공격을 받았을 시 | -0.2f | |
| 제한 시간 종료 시 (승리) | 남은 Hp (0~1) | 이후 종료 |
| 제한 시간 종료 시 (패배) | 남은 Hp (0~1) - 1 | 이후 종료 |
| 제한 시간 종료 시 (무승부) | 0 | 이후 종료 |
| 본인이 사망 | -1 | O |
| 적을 킬 | 1 + 남은 Hp (0~1) | O |
Hyperparameter
접기/펼치기
behaviors:
KnightAgent:
trainer_type: ppo
hyperparameters:
batch_size: 1024
buffer_size: 10240
learning_rate: 3.0e-4
beta: 1e-3
epsilon: 0.15
lambd: 0.95
num_epoch: 4
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 25
checkpoint_interval: 250000
max_steps: 6000000
time_horizon: 1000
summary_freq: 10000
self_play:
save_steps: 50000
team_change: 100000
swap_steps: 2000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
Result
3M vs 3M
꽤 성공적으로 학습이 되었다.
적절한 타이밍에 방패를 사용하여 적의 공격을 막거나, 빙글빙글 돌면서 회피하며 공격 타이밍을 재는 모습을 볼 수 있다.
3M vs 200K
200K 도 생각보다 잘 피하는 모습을 보인다.
다만 공격에 있어서 3M 이 우위에 있기 때문에 거의 모든 에피소드에서 3M 이 승리했다.
추가 학습
방패를 앞에 들고 있지 않을 때, 뒤에 방패를 집어넣는데,
조금 더 학습을 시켜 보았더니, 이를 이용해 자신의 뒤를 공격하는 것을 막는 모습을 보였다.
1 vs 1 Train (Back Shield Disabled)
방패를 집어넣으면 Agent 뒤에 위치하게 되는데, 이게 다양한 플레이를 보여줄 수 있긴 하나...
일단 기습과 같은 플레이가 불가능하고, 특히 다대다 상황에서 뒷 방패 때문에 기습이 전부 막혀버리는 상황이 발생하였다.
그래서 방패를 집어넣을 시 뒤에 위치하는 것이 아닌 그냥 없어지는 것으로 변경하였고,
또한 너무 무분별하게 공격을 진행하는 것 같아 스테미나 시스템을 도입하였다.
공격을 진행할 때마다 일정 스테미나가 소모되고, 천천히 자연 회복되게 만들었다.
이번 학습에서 미리 이후 진행할 다대다 학습을 위해 trainer type 을 POCA 로 변경하였고, 이에 맞게 Group Reward 도 정의해 주었다.
이후 다대다 학습에서는 단순히 Agent 수만 늘려서 학습시키면 되게 하였다.
Policy
| Situation | Reward | EndEpisode |
|---|
| 매 Action 마다 (Living) | 틱당 -1 / (MaxStep) | |
| 장애물에 닿았을 시 | 틱당 -5 / (MaxStep) | |
| 공격에 성공했을 시 | 0.3f, 0.45f (백어택) | |
| 공격을 받았을 시 | -0.2f, -0.3f (백어택) | |
| 적을 킬 | 3 - currentTimeStepRatio | - |
| 사망 | -3 + currentTimeStepRatio | - |
| 모든 적을 제거했을 시 (Win) | 1 + allyHpMean * 2f | O |
| 아군이 모두 제거되었을 시 (Lose) | -1 - hostileHpMean * 2f | O |
| Timeover 시 아군 팀의 HP 가 더 많이 남았을 경우 (Win) | allyHpMean | O |
| Timeover 시 적팀의 HP 가 더 많이 남았을 경우 (Lose) | -1 + allyHpMean | O |
currentTimeStepRatio = CurrentTimeStep / MaxEnvStep;
Hyperparameter
접기/펼치기
behaviors:
KnightAgent:
trainer_type: poca
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 12
checkpoint_interval: 500000
max_steps: 6000000
time_horizon: 1000
summary_freq: 10000
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 20000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
Result
중간에 Policy 를 한번 수정해서 Reward 가 떨어졌지만, 그래도 위처럼 잘 학습되었다.
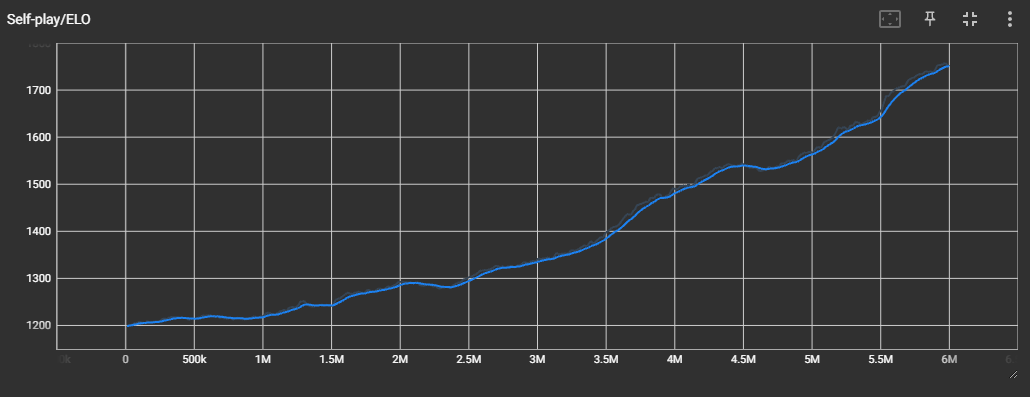
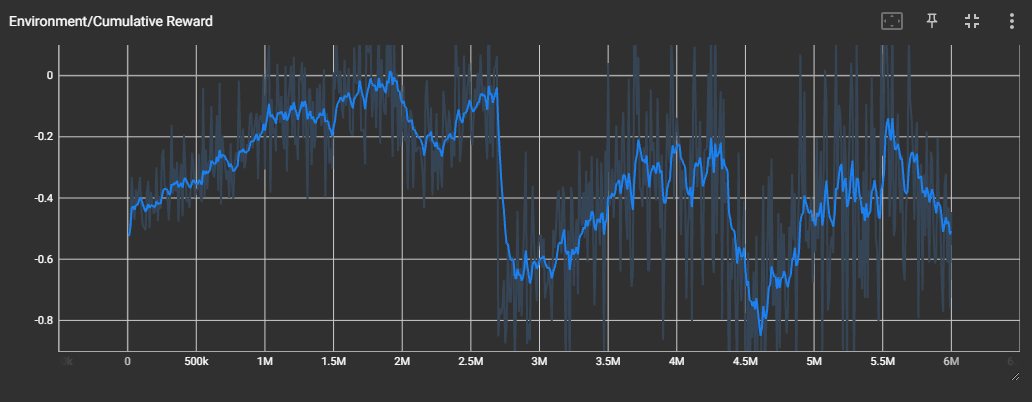
3 vs 3 Train (Back Shield Disabled)
Policy, Hyperparameter
위와 동일
Result
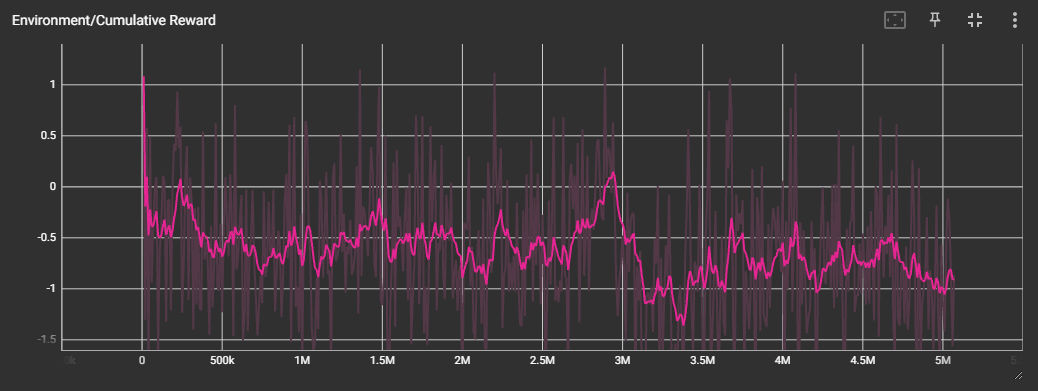
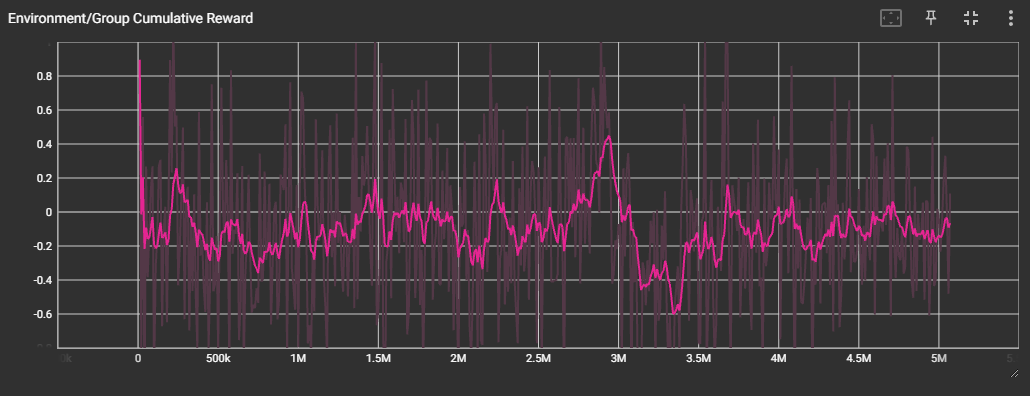
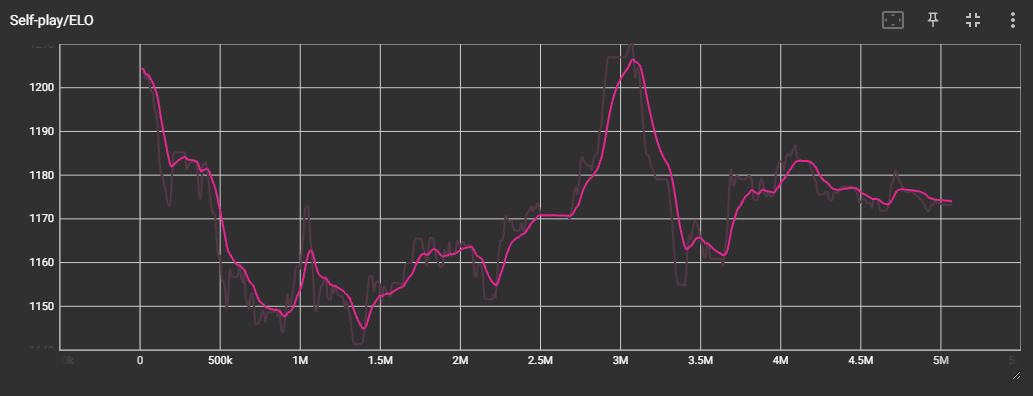
확실히 제대로 학습이 되지는 않은 것 같다.
꽤 오랫동안 학습을 돌려 보았으나, Reward, Group Reward 값이 특정 값에 수렴하지 않고 계속 진동하는 모습을 보였다.
ELO Rate 도 들쭉날쭉한 모습을 보인다.
위 영상은 그 중에서도 가장 ELO Rate 와 Reward 가 높았던 3M 에서의 checkpoint 를 적용하여 테스트해본 것이다.
3명이 적 한명을 둘러싸 공격하는 모습이 조금씩 보이긴 하는데, 이게 모든 상황에서 그러한 것이 아니라 명확하게 학습이 되었다고 말하긴 어렵다고 볼 수 있다.